In the newly renewed Ars Electronica center we visited two exhibitions Understanding AI and Global Shift. Understanding AI was very relevant for our research in the Machine Vision project find a detailed blog-post about it here. The Global shift was interesting from the Machine Vision project because it was a representation of sensing the Earths surface through various technologies and of course satellite images and satellite technology were very prominent in it.
Global Shift Humans have made far-reaching changes to the natural living environment for their own purposes. Apart from the concrete wastelands and the refuse we produce, there are many other examples that testify to this. But it hasn’t always been that way. https://ars.electronica.art/center/en/exhibitions/globalshift/
Several of the artworks in this exhibition was using satellite images and imagery from the orbit to “witness” the Anthropocene, how we humans have been shaping the Earth.
An impressive work, by Seán Doran, ORBIT – A Journey Around Earth in Real Time is a real time video reconstruction of time lapse photography taken on board the International Space Station by NASA’s Earth Science & Remote Sensing Unit, was to be viewed on a huge high definition screen. This epic travel around the Earth talks about the beauty of the earth , however, it also implies the fragility of our ecosystem and how our current presence is the biggest threat to destroy it.
Terra Mars by SHI Weili is a imagination of Mars like Earth. The artist trained an artificial neural network with topographical and satellite imaginary from Earth and then applied it on topographical data of Mars. This remapping creates a visual improbable(?) hallucination of a new planet.
In terms of visualizing the invisible materialities of machine vision from the orbit two works were shown that map all the “stuff” humans have launched into space. Stuff in Space and Quadrature‘s Orbits visualize man-made objects in space, relating to discourses of satellite debris.
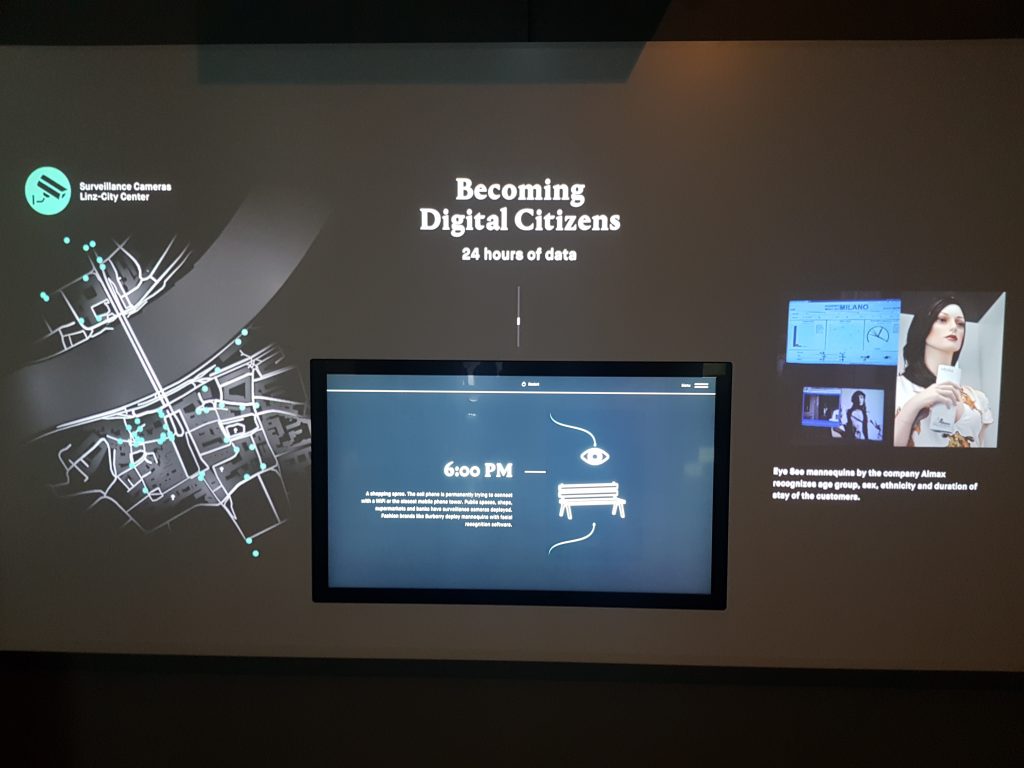
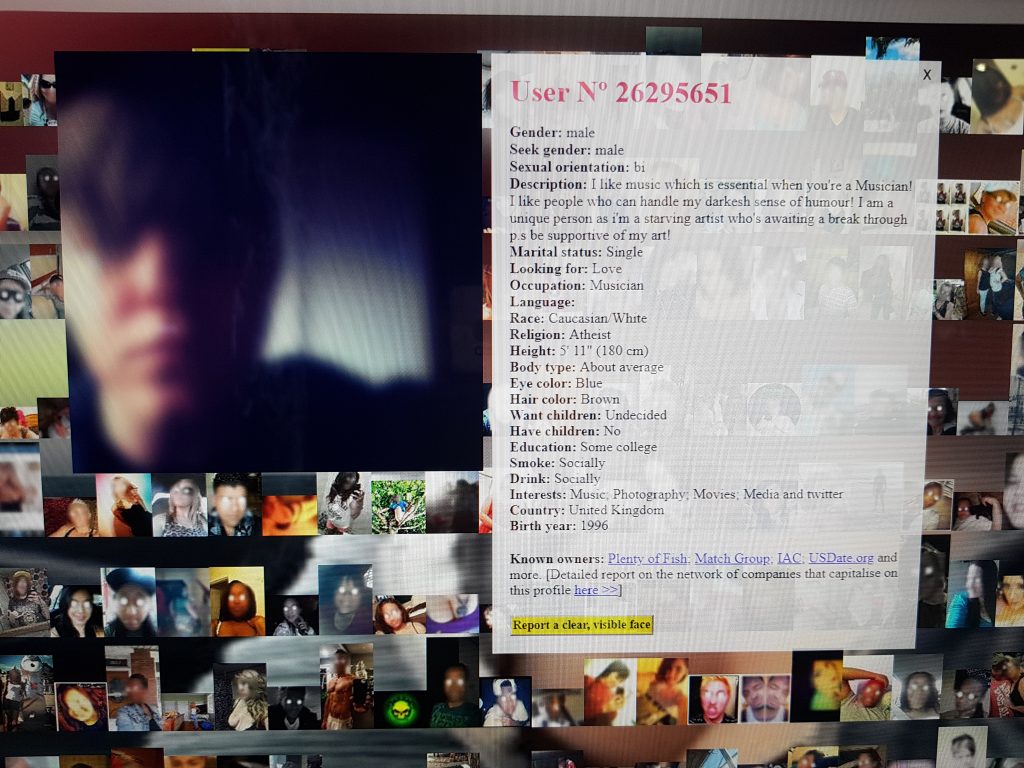
There was also a Digital Citizen part in this exhibition with e.g. Joanna Molls and Tactical Techs The Dating Brokers a million online dating profiles from USDate which the artist payed 136 euros for. This “black market” of profiles including several images make me wonder if they end up fueling machine learning for face recognition. As Adam Harvey has shown in Megapixels the collection of training data is far from ethical or respecting the privacy of people.
—-Acknowledgements—-
Photo credits of this blog post goes to our lovely Machine Vision project assistant Linn Heidi Stokkedal and some of the photos are taken by me as well.
Earlier in the autumn the basement of Ars Electronica Center had been reopened with two totally new exhibition, both relevant for the Machine Vision Project: Understanding AI and Global Shift. We visited these exhibitions both for the festival pre-opening program and late for a deeper dive into the very information rich and detailed exhibitions. All together we probably spent 5 hours there without really able to cover everything in depth.
Understanding AI What is artificial intelligence? And what do we actually know about human intelligence? How intelligent can artificial intelligence be in comparison? And more importantly: what effects will the advances in this field have on our society? https://ars.electronica.art/center/en/exhibitions/ai/
Understanding AI combines artworks, research, visualizations and interactive experiences trying to explain what AI is now as in Machine Learning. The exhibition emphasizes on the positives of AI, however, between the lines also issues of privacy, biases and other “highly questionable” use of AI is brought forth. Whereas the Uncanny Values exhibition in Vienna was bringing fort social, economical, ethical and democratic issues from a discourse around ethical/fair use of AI the Ars Electronica exhibition was very didactic and aimed to explain the technology in a very detailed way.
Following some highlights from the perspective of my research:
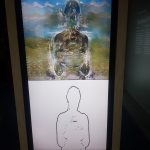
When entering the exhibition the first thing one faces is facial recognition. Later one realizes being part of the WHAT A GHOST DREAMS OF (2019) artwork by artist collective H.O. According to the artist the artwork questions: What do we humans project into the digital counterpart we are creating with AI? It is getting to know our world without prior knowledge and generating data that never existed. What are the effects of using AI to produce works of art? Who holds the copyright? And what is AI, the “ghost,” dreaming about, and what does that mean for us as human beings?
Getting down the stairs to the basement we naturally continue to explore questions about facial and emotion recognition. Mixed on a wall are research papers, websites, industry apps, viral deep fake videos and (artistic) research such as Adam Harvey’s Mega Pixels or Gender Shades by Joy Buolamwini team.The mix brings applications of facial and emotion detection both showing how advanced the technology however questioning the ethical aspects of it as well as. Research shows how “fake” faces produced and getting more realistic bringing also forth problematic uses of deep fakes.
On the long wall one can try Affectiva’s emotion detection app. One can also watch Lucas Zanottos film in which he used very simple everyday objects to express feelings, together with the emotion detection app these works raises questions of how emotions are mapped to our facial expressions.
Further the visitor can read how neural networks were trained to recognize criminal faces in a Chinese study, and how e.g. Amazon Face recognition failed to mach lawmakers faces.
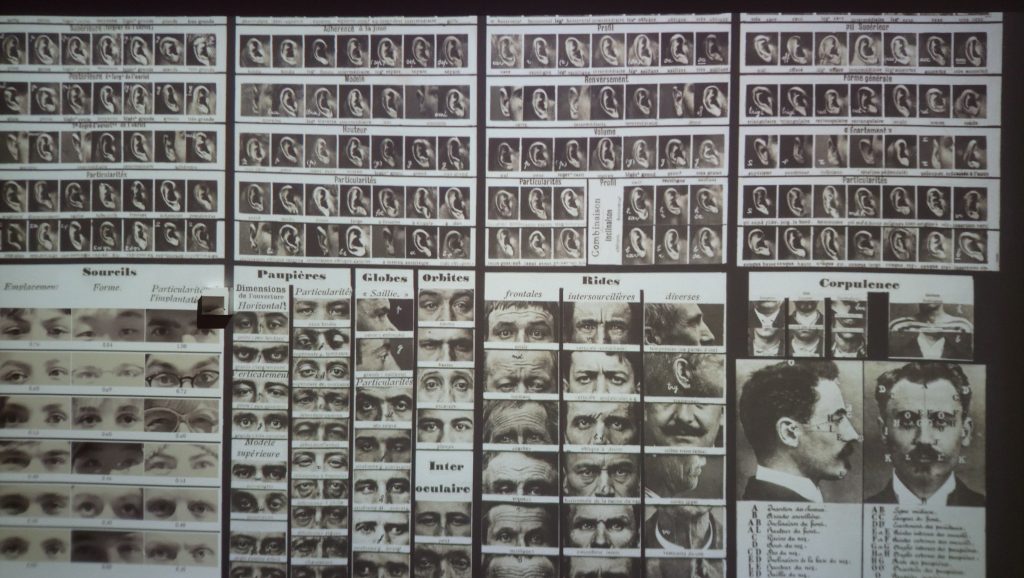
One section of the wall questions what can be read in a face followed by examples such as face2gene and faception the first an app to recognize genetic syndrome from a child’s picture and the second profiling faces into categories such as High IQ, Poker face, Terrorist or Pedophile. Even if info layers refer to Physiognomy here a sharper tone on condemning such applications and revealing their dangers would have been beneficial. Also the the highly alerting study on training AI to recognizes sexual orientation from facial images is only paired with a question if AI understands what it sees, rather than implications of making such an study or application in the first place. How ever a section of the wall is dedicated to problematic use of facial recognition in predictive policing and oppressive use in a surveillance state such as China. The anecdote on the wall referring to public shaming of jail walkers.
One section on the wall is turning our attention to the generation of faces using neural networks. The “Obama Deep Fake” by Researchers at the University of Washington and AI generated news anchors are paired with artist Matthias Nießner face2face in which he plays the puppet master with Trumps face. In addition a research on generating very realistic fake faces by a company called NVIDIA shows how fast such fakes are getting harder to recognize. Here I would like to seen a segment on how spoofing fakes is also very important as described e.g. by artist Kyle McDonald
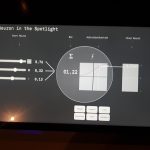
Opposite to the “face wall” a piece called GLOW developed by Diederik P. Kingma, Prafulla Dhariwal; OpenAI, gives a interactive experience linking data sets with characteristics. A set of 16 characteristics can be adjusted for the generated image. Playing around with the thing for a while showed for example that when maximizing the young parameter and glasses the glasses were very faded, however when going towards older the glasses got more visible showing that in the trained data set people tagged old were wearing glasses are more often.
Just the section of faces could have been an own exhibition, however we are just starting to get warm. Another big part of the exhibition was dedicated to explain various AI networks e.g. modeled on moths olfactory system or intelligent navigation systems modeled on rats. Interactive displays were also used to explain how current neural networks are modeled on neurons in the human brain. Here I learned about the scientific image technique “Brainbows”.
A section was dedicated to explain research in the field of cognition and consciousnesses. On one of the screens I got immersed into a work of Kurzgesagt (In a Nutshell) called The Origin of Consciousness – How Unaware Things Became Aware, and it turns out they have a whole channel of shot animations dealing with philosophical and scientific questions.
Further on one could experience trainrt ing of networks on several levels. From how the weights and biases of single neurons change when training a network to training a system to recognize the predators of a mouse. This part of the exhibition was very well done, however, it was like an updated version of a science museum rather than a art exhibition. Though this is very much in style what Ars Electronica center is. An info layer of short texts and images also explained machine learning terminology e.g. what is the difference between Generative Adversarial Network, Recurrent neural network and a Convolutional neural network or explaining terms such as Latent space or
Activiation Atlas.
“How machines see” was also a topic in several works in the exhibition. A wall of screens depicted how various layers in a neural network recognized various features. The work visualized live layers, convolution and filters, and how the artifacts shown in front of a web-camera finally was recognized and labeled either successfully or not. Hence visitors could test the accuracy of the trained network and at the same time get insight onto how current AI “sees” and “understands” objects.
This work on Neural Networks Training developed by The Ars Electronica Future Lab was the most impressive attempt to open the black box of machine learning in computer vision.
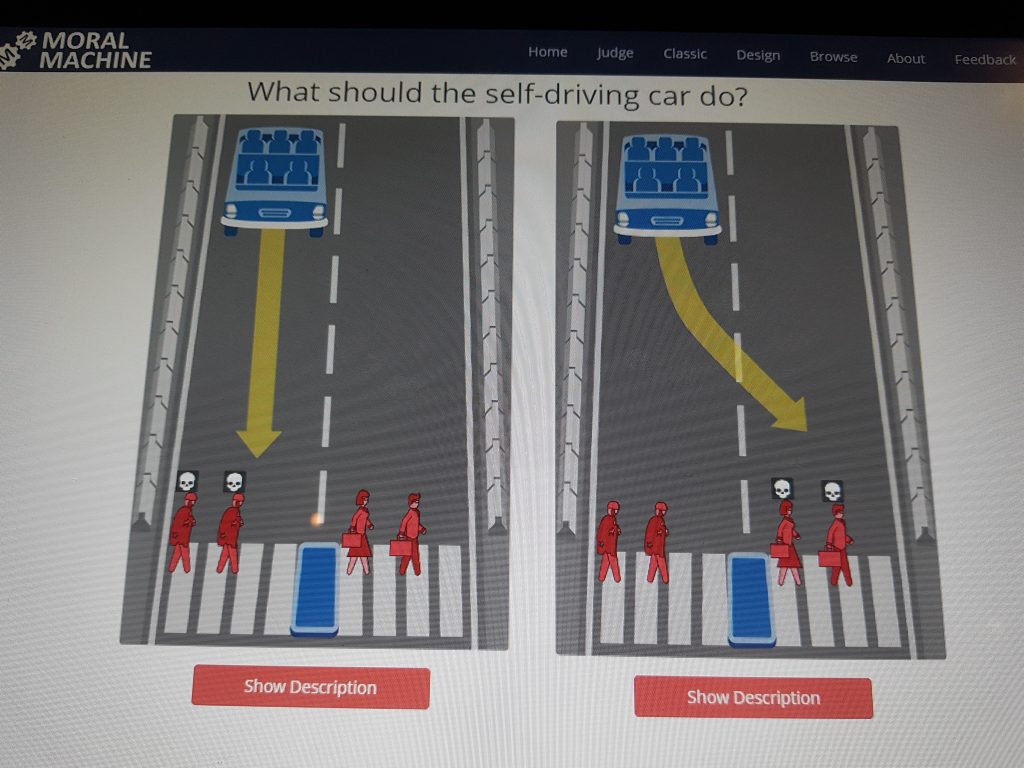
How machines “see” environments e.g. is of course a big issue in computer vision. A section of the exhibition was exploring the challenges to develop self driving cars and obviously in traffic it is crucial that the communication between pedestrians and eventually self driving cars is smooth. Various aspects of the challenges to design an autonomous car was on display ranging from “Looking Through the Eyes of a Tesla Driver Assistant” to MIT’s Moral Machine a platform for gathering human perspective on moral decisions made by machine intelligence such as self-driving cars.
Korean collective Seoul LiDARs uses industrial technology in various artistic experiments. Their Volumetric Data Collector a bulky wearable is using 3D laser sensors (Lidar) which are usually implemented in autonomous vehicles. A video work illustrates how such tech extends the sensory organ of a human body while walking in Seoul e.g. on the shamanistic mountain Ingwasan.
Kim Albrechts Artificial Senses approaches artificial intelligence as an alien species trying to understand it by visualizing raw sensor data that our machines collect and process. In his work he “tames” the machine by slowing it down to be grasped by human sensory. We move away from the vision to other senses, however, the when sensor data of location, orienting, touching, moving and hearing are visualized the work brings me to the question of what is machine vision. In a digital world in which machines actually just see numbers any sensor input can be translated to visuals. Hence what the “machines sees” are data visualizations and any sense can be made visible for the human eye. However, the machine dose not need this translation. Kim questions the similarity of the images:
“A second and more worrying finding is the similarity among many of the images. Seeing, hearing, and touching, for humans, are qualitatively different experiences of the world; they lead to a wide variety of understandings, emotions, and beliefs. For the machine, these senses are very much the same, reducible to strings of numbers with a limited range of actual possibilities. “
Both sensing and mirroring human behavior is demonstrated in Takayukis SEER: Stimulative Emotional Expression Robot. In this work the machine is using face detection and eye tracking to create an interactive gaze creating an illusion that the robot is conscious of its surrounding. Facial motion tracking mirrors our emotions towards the robot and expresses it back simply using an soft elastic wire to draw a curve the robots eyebrows. According to the artist the experiment is not to answer the philosophical theme “Will a robot (or computer) obtain a mind or emotions like mankind”, rather it is reflecting back a human produced emotion.
The exhibition would not be complete if it would not raise the question: Can AI be creative? Followed by the recognizable Neural Aesthetics. Among others these section features projects such as Pix2Pix Fotogenerator,Living Portraits of e.g. Mona Lisa and Marilyn Monroe, and interactive installations such as Memon Akten’s Learning to See: Gloomy Sunday (2017) and ShadowGAN developed by the Ars Electronica Future Lab. When such tools generate new unique artifacts it is tempting to read machine creativeness into it, however several artist statements describe how human and machine creativity intertwine and that the artist is still doing a lot of decisions. This would rather lean towards being a new generative art technique and we will for sure see more tools such as NVIDIA’s GauGan which also could be tested in the Ars Electronica center.The development of such tools are directed to motion/graphic designers in advertisement agencies to produce cost efficient images. Drawing photo realistic landscapes or generating realistic photos of non-existing people helps agencies to avoid image and model royalties and expensive trips to photo shoot in exotic locations.
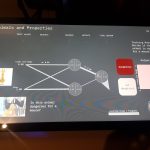
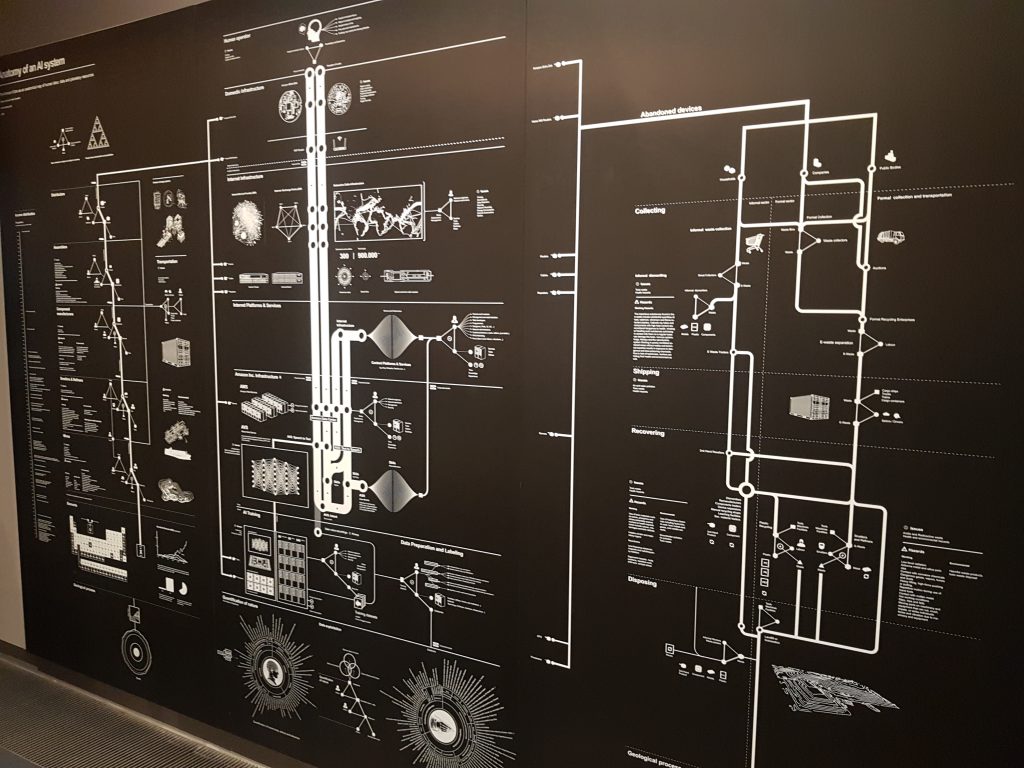
Last (depending of how one navigates trough the exhibition), but not least, a wall dedicated to the wonderfully complex Anatomy of an AI system (2018) illustrations by Kate Crawford and Vladan Joler.
—-Acknowledgements—-
Photo credits of this blog post goes to our lovely Machine Vision project assistant Linn Heidi Stokkedal and some of the photos are taken by me as well.
After a two year break I was looking forward to attend for the fourth time one of my favorite conferences xCoAx. It is a rather small, yet friendly gathering of artist, designers and researchers interested in “an exploration of the intersection where computational tools and media meet art and culture” (http://www.xcoax.org/). Why I like this conference so much that it only has one track of presentation, meaning that there is a possibility to hear everyone talk, there is an exhibition and performances as part of the event and the artists also get a short slot to present their work. And since a couple of years there has been a doctoral symposium in the beginning of the conference and this year I had the chances to present there. In addition to getting feedback on my thoughts regarding my phd project I also had the opportunity to present with Andreas (as KairUs) a paper about our Behind the Smart World project and exhibit our workForensic Fantasies in the exhibition.
Here are some personal notes, thoughts and photos (by KairUs) I was gathering during the 3 day conference.
PHD Symposium
The PHD symposium was a new program number for me, so I was not sure what to expect. I had prepared a 15 minute presentation of my project in general and wished to get some feedback on presented methods and both suggestions and considerations regarding my research questions and topics.
Simona Chiodo Professor of Philosophy at the Politecnico di Milano, specialised in Aesthetics and Epistemology and Philip Galanter artist, theorist, educator, curator and an Associate Professor at Texas A&M University as our doctoral symposium chairs allowed us the given 15 minutes to present our project or a specific part of it, and then they gave each candidate about 15 minutes of time with their feedback and comments. We were six PhD candidates presenting, however, having just the afternoon time, with the requirement to finish in time for the exhibition opening started, we had to keep a strict regime with the time. A bit more time for a Q&A or an discussion among the PhD candidates as well as some breaks would have been appreciated. This relatively new program block will for sure develop further in the upcoming conferences. Even with given constrains the symposium was fruit full and all of the candidates stayed for the rest of the conference so we could ask our questions and get into discussions after the symposium. Before starting the session the chairs made it clear for us that they would give us feedback from the perspective of their discipline an in digesting their suggestions and comment we should always be true to our own institution. And in some cases even their feedback was conflicting, however, the symposium was conducted in a very friendly atmosphere.
The feedback I got from the symposium chairs was positive. Simona Chiodo encouraged me to follow the themes I had chosen. Philip Galanter recognized that I was talking about two kind of machine vision limits, technical which are breakable in terms of that technology can always evolve and some limits might be overcome. The other type of limits are more ethical, based on human values and cannot be broken, hence, he wanted me to be more selective or at least recognizes and define these differences.
In addition to me five other candidates presented:
In his presentation The Sounds of Obsolescence in the Age of Digital Re-Production, Paul Dunham (Victoria University of Wellington, New Zealand School of Music) discussed how to apply theories of Media Archeology to his object based sound installations. In connection to Paul’s presentation I noted a general comment from Simona that: The process of defining something is more important than the definition. Referring to that there is no definite definition and the process is more about abstracting.
Naja Le Fevre Grundtmann (University of Copenhagen, Department of Arts and Cultural Studies) presented a part of her research under the title: Aby Warburg’s Mnemosyne Atlas: An Iconology of Difference. I really appreciated her approach of close reading Aby Waburgs PanelC and linking it to search results of Mars in Google search. She argued that we can just extract a very small part of the human mind and make it computable, therefore, we can’t substitute all mental processes with algorithms. “We can use computing to say what is computable”.
Sabina Hyoju Ahn (University of Art and Design Linz) presented under the title Multi-Sensory Transformation of Biological Signals her practice based research situated betwixt Art and Science including projects using Atomic forced microscopy which was partly relevant for me from the Machine Vision perspective. A comment from Philip, which was directed to me and other participants as well, was to take a look at the History of Generative art for how ideas of algorithms and computing has been around for a long time in context of art.
Kim Albrecht described some machine learning techniques he has been using as a part of his design practice in a presentation called Design as Drawing Distinction. I found it interesting how he described the process of working with machine learning algorithms, how there is potentially millions of drawing and creating views, however, the designer/artist makes a lot of decisions affecting the outcome even in the very simple geometric works Kim presented both in the symposium and in the exhibition.
Tomasz Hollanek in Speculating on Artificial Intelligence from Early Photography to Contemporary Design started his presentation of how “Culture is black boxing” by reflecting on Vilém Flusser all technology is trickery statement. He described the black boxes as forms of bureaucracy and questions if design by uncovering, unboxing, undesireing, ever can materialize critique.
After the PhD symposium the opening of the art exhibitions were accompanied by heavy rain. Which did cause some damage as we figured out the next morning. Lucy for us we had due to other reasons moved our artwork and therefore avoided any damage. However there were several interesting artworks divided into two spaces, the white cube and the black box. Our work Forensic Fantasies was also exhibited.
Highlights from the conference
Paper Session 1 was very relevant for me discussing different aspects of AI from Generated AI art and fooling AI to feminist perspectives on AI. After the session I had the chance to try out Hanna’s & Co. photo booth a playful way to figure out how object recognition is working…or not.
The Spectre of Zombies is Haunting AI Art: How AI Resurrects Dead Masters, and Alternative Suggestions for AI Art and Art History by Tsila Hassine & Ziv Neeman Can you fool the AI?: Investigating People’s Attitude Towards AI with a Smart Photo Booth by Hanna Schraffenberger, Yana van de Sande, Gabi Schaap & Tibor Bosse
Imagining Intersectional AI by Sarah Ciston
Some Things You Can Ask Me: About Gender and Digital Assistants by Pedro Costa & Luísa Ribas
Tsila Hassine talking about art generated by neural networks and zombiesSarah Ciston imagining intersectional AI and feminist data visualizations
Pedro Costa talking about Gender and Digital Assistants
Testing Hanna’s & Co. AI photo booth.
In session 2 there was a couple of interesting papers on Surveillance Capitalism:
Deep Solutions: Artistic Interventions in Platform Surveillance
Craig Fahner & Matthew Waddell
Surveillance Capitalism and the Perils of Augmented Agency
Rodrigo Hernández-Ramírez
In session 3 papers on algorithmic curating and ethics in computation were interesting and worth re-visiting the papers. Gaia talk was about her experience as a curator in the exstrange project which we were also part of in 2017 (http://kairus.org/exstrange-online-auction-exhibition/).
Human-Algorithmic Curation: Curating with or Against the Algorithm?
Gaia Tedone
Catherine Griffiths Approaches to Visualise and Critique Algorithms in Ethically Sensitive Spaces
In paper session 4 we presented our paper and afterwards was the Keynote of the day: Luciana Parisi researches the philosophical consequences of technology in culture, aesthetics and politics. She is a Reader in Critical and Cultural Theory at Goldsmiths University of London and co-director of the Digital Culture Unit.
Keynote: Luciana Parisi
Information Diving on an E-waste Dump in West Africa: Artistic Remixing of a Global Data Breach by Andreas Zingerle & Linda Kronman
In the evening we attended a series of performances: Laser Drawing by Alberto Novello Never The Less: A Performance on Networked Art by Luís Arandas, José Gomes & Rui Penha SKR1BL by Jules Rawlinson Bad Mother / Good Mother by Annina Ruest Serrate Nº 2 by Jingyin He
Both due to the topic and led light pimped breast-milk
pumps Annina’s performance evoked most thoughts in my mind.
Friday started with paper session 5 and Antonio Daniele’s & Yi-Zhe Song’s Artistic Assemblage paper was interesting while referring to Katherine . Hayles’ non-conscious assemblages among other theories.
Antonio Daniele defining Artistic Assemblage
In paper Session 6Rosemary Lee’s presentation Aesthetics of Uncertainty we heard about her work with neural networks. Her website is worth re-visiting with the machine vision database in mind.
In the afternoon we presented ones more Forensic Fantasies in the Artwork Presentations slot. The performance presentations we missed while we had to set-down and ship our artworks back to Austria. However we made it back for the second Keynote by contemporary art critic and curator Domenico Quaranta who talked about how the Venice Biennal played out through social media channels. A couple of days later we actually had the time to visit the Biennal with his words in mind. The conference ended with a very nice conference dinner with lively discussions.
Artwork presentations with:
Andrés Villa Torres
André Rangel & Simon Rangel
Andy Simionato & Karen Ann Donnachie
Angela Ferraiolo
Carl Rethmann
Chris Williams
Francisca Rocha Gonçalves & Rodrigo Carvalho
Kim Albrecht
Linda Kronman & Andreas Zingerle
Marc Lee
Martin Bricelj Baraga
Martin Rumori
Paul Heinicker, Lukáš Likavčan & Qiao Lin
Philip Galanter
Philippe Kocher & Daniel Bisig
Tim Shaw
Following I describe some experiences from the POM Beirut conference. In the text I refer to the tracks and keynotes I was able to participate in, so it is far from covering this multi-track event. The purpose of this text is rather to have some personal notes for my PhD research.
“The POM-conference addresses the politics of the machines and the inescapable technological structures, as well as infrastructures of artistic production in-between human and non-human agency with critical and constructive perspectives. Where and when do experimental and artistic practices work beyond the human: machine and human: non-human dualisms towards biological, hybrid, cybernetic, vibrant, uncanny, overly material, darkly ecological and critical machines? How are we to analyze and contextualize alternative and experimental ontologies and epistemologies of artistic practices beyond transparent dualisms and objectification? How are the relationality and operationality of machines being negotiated into cultural and social ontologies?”
https://pombeirut.com/
The second POM – Politics of The Machines conference founded by Laura Beloff and Morten Søndergaard took place in the capital of Lebanon, Beirut. When my abstract was accepted I was exited first because this would be my first chance to present and get feedback on some of the research I had been working since starting at the Machine Vision project. Second I would have the chance to revisit Beirut a vibrant city that had traveled too several times in the early 2000: how much would it have changes the past almost 15 years?
I arrived in the middle of the night and the next morning during breakfast I had the chance to meet up with my Machine Vision colleague Marianne Gunderson who was also presenting at the conference and a nice surprise was that Cesar XX a friend from Linz was staying in the same hotel.
Often together we walked through the streets of Beirut for about a half an hour which it took to get from our Hotel in Hamra to the main conference venue which was the Lebanese International University.
The first conference event took place on 11th of June when we were invited to the opening reception and greeted by the Patronage of the event His Excellency The Minister of State for Foreign Trade Mr. Hassan Mourad. A very official start soon became more relaxed when having the opportunity to eat some excellent Lebanese food with the other participants.
The next morning the actual conference program started. I was lucky to present in the first session, however there were some startup hiccups with the organization of the event. We were changing the room and had some tech issues, yet ready to start on time. A less fortunate thing, perhaps due to inexperienced planning, was that me and the moderator ended up being the only ones showing up for the panel. However this worked out to my advantage having some extra time to finish my presentation and plenty of feedback and an interesting discussion.
Presenting my paper: The deception of an infinite view – exploring machine vision in digital art. In The Battlefield of Vision: Perceptions of War and Wars on Perception Track moderated by Matt Wraith.
The advantage to present early on in the conference is the relaxed feeling of “having it done”, as well as others approaching you personally knowing a bit more about my research interests.
In the afternoon the The Battlefield of Vision: Perceptions of War and Wars on Perception track continued with presentations from. Konrad Wojnowski, Matthew Wraith, Rebecca Sanchez and Dejan Markovic . Konrad and Matthew presenting perspectives on the track theme embarking their presentations from Futurism and Avant-garde art, and Rebecca and Dejan talking about their experiences as a media editor experiences and artist. Graz based Dejan’s work was actually very relevant from my machine vision research. His work Shapes of Things Before My Eyes (2017) is a 4-channel video through the eyes of a rescue robot, ‘Wowbagger’.
Matthew Wraith moderator of the track presenting: The weaponization of artDejan Markovic: Towards the Sensory Apparatus.
In the second afternoon track I could learn more about artworks using machine learning. Two very interesting presentations from Tivon Rice (http://www.tivonrice.com/) and Jukka Hautamäki (https://jukkahautamaki.com/), both presenting highly interesting use of neural networks in a body of artworks. Definitely revisiting their websites when adding works to the machine vision database. Tivon is also one of the first artists to collaborate with Google AMI – The Artists and Machine Intelligence research group and has elaborate insight in Artificial Neural Networks. He has used tools such as the neural-storyteller that tells stories about images and can use mimic the style of an author’s writing or an music artist’s lyrics. In Environment built for absence (an unofficial/artificial sequel to J.G. Ballard’s “High Rise”) he uses J.G. Ballard’s style to describe 3D scans of the 2017 demolished Netherland’s Central Bureau of Statistics office.
Tivon’s work was definitely the highlight of the quite modest exhibition in the university Multipurpose room.
Selected works from the POM exhibition: (left) Environment Built for Absence(an unofficial/artificial sequel to J.G. Ballard’s “High Rise”) byTivon Rice, (middle) AAVM – Automatic Art Validating Machine (2019) by Tarek Mourad,, (right) Connect, a Virtual Family Album by Dimitri Haddad, 2015-2016.
Jukka presented his GAN work and argued that emerging easy to use GAN generators can make anyone an AI artist. Though I think in everyone hands the neural aesthetics can become just a kitschy style, and artist must find more insightful was of using it. However a playful GAN app in everyone phone might work as a media literacy tool (perhaps it could be used in parallel with discussing Deep Fakes).
Day 2 of the conference ended with Soh Yeong Roh very personal Keynote How I stumbled into Neotopia describing her journey as Nabi Art centers director. Perhaps cultural and disciplinarian differences became evident in the Q&A session. Audience members were questioning if finding solutions by developing technologies for problems that are caused by it is the right way to go as well as inquiring about Soh Yeong Roh’s definition of art.
Morning of Day 3 and (the second day of conference tracks), I choose to join a combo panel presenting papers from two tracks: Artificial intelligence for art AIA: Computational creativity, Neural networks, Simulating human activity and Fourth Industrial Revolution (IR 4.0): Art, Cyberphysics, Automated creativity. Both track abstracts were interesting, however there was little for me to bring out of the presentations even if Juan Carlos Duarte Regino’s presentation Radio Neural Networks was well done and interesting as he explained how his work with neural networks and sounds was inspired by composers such as John Cage.
Vienna based Ingrid Cogne and Patrícia J. Reis. moderated several panels for their track: Body-politics of the machines:Troubles WITH/IN/OUT art, body, perception, politics, and technology. They had invested a lot of time in planning their panels which was of advantage of course for them but for the audience as well. I had the chance to see a panel with Afif Dimitri Haddad who in Transcending the Body Through Movement, Perception and Te c h n o l o g y described experiences of working with technology from the perspective of contemporary dance. Diego Maranan presented his and Agi Haines’, Frank Loesche’s, Sean Clarke’s, Patricia Calora’s, Angelo Vermeulen’s, Pieter Steyaert’s and Jane Grant’s collaborative work RE/ME: An immersive installation for reimagining and resculpting bodily self-perception that they formed in the context of Hack the Brain EU-event (https://re-me.cognovo.org/). The most relevant presentation in this track was Mitra Azar’s POV-matter and machinic POV between affects and Umwelts. His presentations filled with relevant theory offered a analysis how the panopticon has changed towards a POV-opticon revering to the Point of View (POV) from cinematic studies. Definitely need to revisit his writings to get my head around this very intense 15 minutes.
Afif Dimitri Haddad referring to a performance manipulating micro-muscles which are used to express emotions.Diego Maranan talking about how the body shapes the mind.Mitra Azar arguing how the panopticon is now a POV-opticon while all of us has a smartphone with a camera in our pockets.The panel discussion moderated by: Ingrid Cogne and Patrícia J. Reis.
Next we had a transport to the second main venue of the conference the Orient Institute where i joined Jan Løhmann Stephensen’s lecture Towards a philosophy of post-creative practices as a part of the Fourth Industrial Revolution (IR 4.0): Art, Cyberphysics, Automated creativity track. A presentations that embarked on a quest of exploring human machine creativity taking the case of Portrait of Edmond Belamy ‘s auction at Christies as a starting point. As intended the presentation lead to a discussion about the abilities of AI to autonomously create something unique which could be called art, in the following Q&A session.
Questions from Jan Løhmann Stephensen presentation.
Day 3 ended with the second Keynote Art and Barbarism by Hubertus Von Amelunxen with the background in French literature, art history and philosophy Professor Von Amelunxen presented Algerian artist Adel Abdessemed’s work questioning “Can art survive culture or can culture survive without art?” The Orient Institute provided an island of calm, green and culture in the middle of Beirut’s busy streets, providing a stage to as what arts role in culture and politics is.
Keynote: Hubertus Von Amelunxen
The day ended with an reception at the institute, yet again serving my favorite Lebanese food. Afterwards loosing track of where most of the participants headed for continuing the discussions of the day I ended up with an little group to visit a very interesting location on Hamra in Beirut: Metro al Madina – Cabaret & Pub, and had a chance to have a sneak peek on the show of the night.
Reception at the Orient InstituteMetro al MadinaLebanese cabaret at Metro al Madina
In the Permanent Telesurveillance: Privacy, data protection, panopticon track César Escudero Andaluz in his Data polluters: Privacy, vulnerability and counter-surveillance presented his method of analyzing art/design hacks. A method that would be relevant for me to look at, when as planed i start to write about facial recognition hacks in my third article. While we are friends from the time I was living in Linz and position our selves in the same media art community we had several interesting discussions during the confreres and he both reminded me and made me aware of several relevant artist and artworks I should have a look at.
Cesar presenting artworks dealing with privacy, surveillance and tech vulnerabilities.Hacking strategies listed in Cesar’s presentation.
In the afternoon I had the chance to see my team member Marianne Gunderson’s presentation: The Internet of Eyes – hostile devices in digital horror stories in the Internet of things: Dystopian Artificial Intelligence, Black Boxes track and then still move location and catch the panel discussion part of the Living machines: Wars within living organisms track with Pieter Steyaert, Angelo Vermeulen and Diego Maranan presenting Excavating abandoned artificial life:a case study in digital media archeology and Freja Bäckman’s Frail Frames.
Marianne presenting how machine vision is portrayed in creepy-pasta stories.
Living machines: Wars within living organisms track panel
My last panel of the conference was Body-politics of the machines: Troubles WITH/IN/OUT art, body, perception, politics, and technology with Tiago Franklin Rodrigues Lucena presenting Designing a text-neck:the body-entertained and modified by the use of smartphone. Philosophy student Alina Achenbach in her Decolonizing the Digital? – Artistic Positionality& Post-Enlightenment Pathways for the Internet touch upon aerial images and provided me with an interesting reference to Caren Kaplan’s Aerial Aftermaths that I have been reading and found very relevant. Design duo Michelle Christensen and Florian Conradi presented a series of smart home hacks in their presentation Open So(u)rcery: The Entangled Body as a DIY Counterapparatus.
Alina Achenbach presenting Decolonizing the Digital? – Artistic Positionality& Post-Enlightenment PathwaysAlina referencing Karen CaplanDesign duo Michelle Christensen and Florian ConradiBody-politics of the machines: Troubles WITH/IN/OUT art, body, perception, politics, and technology panel
The conference ended with a closing party at the onomatopoeia – the music hub with some very improvised performances, philosophical debates as well as less serious chats among the participants. When the party moved to a rooftop rather far away I did a smart decision of returning back to the hotel. Due to this I was still able to make use of the next morning, catching the view of the sea before leaving for the airport to return home
Combining working on our Machine Vision database with amazing food, spa and swimming in the fjord at Solstrand was amazingly productive. Two days together with the Machine vision team and with the help of methods expert Annette Markham our database work took big leaps forward. However a lot remains to do and I am very happy that two more autumn sessions at Solstrand are booked.
While visiting Berlin for the transmediale we stumbled on the Ars Electronica Export exhibition at the DRIVE Volkswagen Group Forum. The artworks were were very professionally curated into the space and it was not too disturbing with the show case cars in between. To my joy there was a number of artworks that related to Machine Vision. Some of them I have seen at earlier editions of Ars Electronica, yet some of them were new to me. Below some of my documentation from the exhibition with artwork abstracts copied from the exhibition webpage.
Echo
by Georgie Pinn
Echo is a bridge to another person’s memory, identity and intimate experience. The key intention of the work is to generate empathy and connect strangers through an exchange of facial identity and storytelling. Seated inside a graffitied photo booth and guided by an AI character, you slowly see another’s face morph into your own, driving your features with their expression. When you record your own story, layers of yourself are echoed in the other. What story will you share with a stranger?
Creative Producer: Kendyl Rossi (AU/CA) www.electric-puppet.com.au
Jller
by Prokop Bartoníček , Benjamin Maus
Jller is part of a research project on industrial automation and historical geology. The apparatus sorts pebbles from the German river Jller by their geologic age. The river carries pebbles that are the result of erosions in the Alps, and those from deeper rock layers once covered by glaciers. The machine uses computer vision to sort the stones by colors, lines, layers, grain and surface texture, and classifying them into age categories using a manually trained algorithm. www.prokopbartonicek.com www.allesblinkt.com
Narciss
by Waltz Binaire
The human ability of self-perception and our urge to question, research, pray and design have long been unique in the world. But is this still true in the digital age? Narciss is the first digital object that reflects upon its own existence by exploring its physical body with a camera. An AI Algorithm translates the observations into lyrical guesses about who it thinks it is. The algorithm simulates human cognition from a behavioural perspective. The resulting rapprochement of man and machine questions our self-image and our raison d‘être. waltzbinaire.com
Mosaic Virus
Anna Ridler
Mosaic is the name of the tulip virus responsible for the coveted petal stripes that caused the speculative prices during the ”tulip mania” in the 1630s. This work draws a parallel to the current speculations around cryptocurrencies, showing blooming tulips whose stripes reflect the value of the Bitcoin currency. Echoing how historical still lifes were painted from imagined bouquets rather than real ones, here an Artificial Intelligence constructs an image of how it imagines a tulip looks like.
This work has been commissioned by Impakt within the framework of EMAP/EMARE, co-funded by Creative Europe.
Myriad (Tulips)
by Anna Ridler
This work is the training data set for the parallel work Mosaic Virus. Ten thousand, or a myriad, tulips were photographed and sorted by hand by the artist according to criteria of color, type and stripe — a work that is the basis of any database for machine learning. The images reveal the human aspect that sits behind machine learning and how the labels are often ambiguous. How objective can artificial intelligence actually be when it is repeating the decisions made by people? And how difficult is it to classify something as complex as gender or identity when it is hard to categorise a white from a light pink tulip?
The Normalizing Machine
by Mushon Zer-Aviv, Dan Stavy, Eran Weissenstern
Early scientific methods to standardize, index and categorize human faces were adopted by the Eugenics movement as well as the Nazis to criminalize certain face types. Alan Turing, considered the founder of computer science, hoped that algorithms would transcend this systemic bias by categorizing objectively, and end the criminalization of deviations like his own homosexuality. But how do algorithms identify a “normal“ face? And how do we? mushon.com stavdan.com eranws.github.io
VFRAME – Visual Forensics and Advanced Metadata Extraction
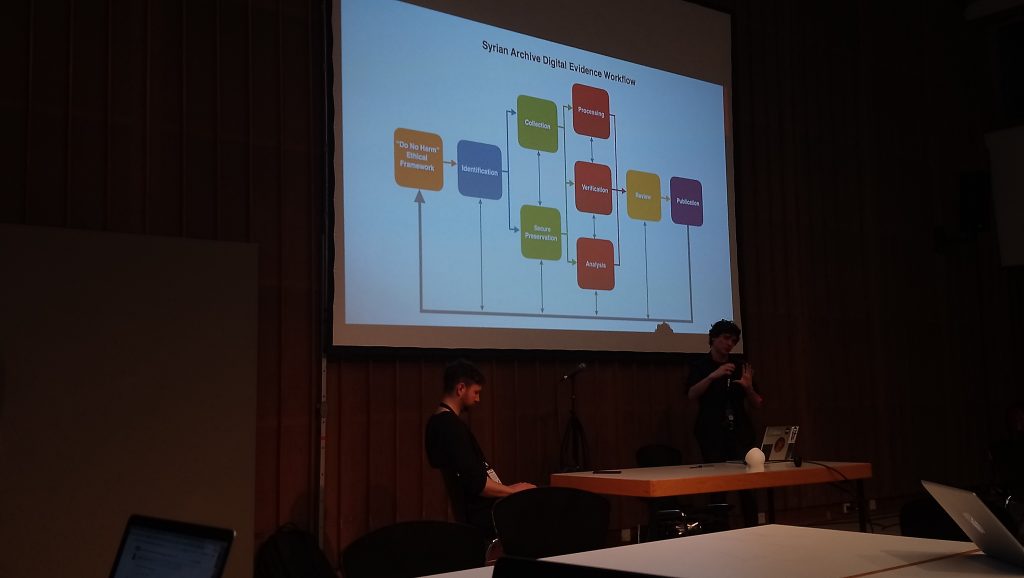
by Adam Harvey
VFRAME is an open source computer vision toolkit designed for human rights researchers and journalists. VFRAME is currently working with the Syrian Archive, an organization dedicated to documenting war crimes and human rights abuses, to build AI that can automatically detect illegal munitions in videos. Their current research explores the use of 3D modeling and physical fabrication to create new image training datasets. ahprojects.com
The transmediale 2019 was a festival with out a topic. The organizers wanted to leave it open this year avoiding to give a specific direction or tone for emerging thoughts and content. The theme of the festival program was built around the question of: What moves you? Emotions and feelings were examined in talks, workshops and performances to open up discussion about the affective dimensions of digital culture today.
Transmediale at Haus der Kulturen der Welt
Of course it is impossible to attend all of the program, so I console my self with the knowledge that part of the program I missed i can usually catch later on transmediales YouTube channel where they publish most of the talks and panels.
Following some of my transmediale 2019 highlights:
Workshop(s)
I had the chance to get to Berlin a bit earlier to attend Adam Harvey’s (VFRAME) and Jeff Deutch (Syrian Archive) workshop Visual Evidence: Methods and Tools for Human Rights investigation. The workshop centered around the research and development of tools to manage a huge amount of video material from conflict areas, specifically Syria. The Syrian Archive collects material intending to documented and archive evidence for possible future use in trying to hold war criminals accountable for their actions. The challenge for human rights activists working with footage from Syria is that there is a massive amount of material. Manually sorting out the relevant videos for archiving is just requiring too much time. To tackle this challenge the Syrian Archive started a collaboration with artist Adam Harvey to develop computer vision tools aiding the process of finding relevant material among hours of footage. Videos often filmed by non professionals in violent, often life threatening, situations (a very specific video aesthetic which is relevant when training object recognition).
Adam Harvey describing the process of developing object recognition toolJeff Deutch describing the workflow of verifying evidence.
After learning about the archiving challenges of human right activists Adam took us trough the process of developing VFRAME (Visual Forensics and Metadata Extraction) which is a collection of open source computer vision tools aiming to aid human rights investigations dealing with unmanageable amounts of video footage. The first tool developed was simply per-processing frames for visual query. A video was rendered to one image showing a scene selection. This helped the activist to see the different scenes of a video in one gaze enabling them to process the information of a several minute long video in just 10 seconds. Now the workflow was much faster, yet it would still take years to process all of the video footage. What the activist were looking for in the videos was evidence of human right abuses, children rights abuses, and also identifying illegal weapons and ammunition. To automatize some of the work load, as a first step, Adam and the Syrian Archive has started an object recognition training of a neural network to identify weapons and ammunition. Adam used the example of A0-2.5RT cluster munition as an example to talk about the challenges they had.
Adam showed us a tool that they have been using for annotating objects, but it has been time consuming and a greater challenge was not having enough images to actually train the network. While working with the filmed footage the activist had learned to see patterns how the object (in this case A0-2.5RT) was appearing ( eg. environments, light conditions, filming angel etc.). Hence one successful solution was to synthesize data, in other words to produced 3D renderings of the ammunition simulating the aesthetics of the documented videos. The 3D renderings with various light conditions, camera lenses, filming angels provides the neural network with additional data for training. Adam also showed experiments with 3D prints of the A0-2.5RT, but according to him it is way more effective to use the photorealistic 3D renderings.
3D print: part of a A0-2.5RT cluster ammunition.
In a panel discussion later during the conference (#26 Building Archives of Evidence and Collective Resistance ) Adam was asked how he felt about developing tools that could possible be missed used. From Adams perspective he was actually appropriating tools that are already misused. VFRAME provides a different perspective for use of machine vision in a very specific context. During the Q&A the issue of bias data sets was questioned. With the context of this case study Adam made it clear that bias actually needs to be included in the search of something very specific. For him the training images needs to capture the variations of a very specific moment, for him bias included e.g. the camera type that is often used (phone), height of the person filming (angel) the environment where the ammunition is often found (sometimes on the ground, or someone holding it in their hands etc.). When trying to detect a very specific object in a very specific type of (video) material, then bias is actually a good thing. Both during the panel and in the workshop it was made clear that the processing large amounts of relevant video material and talking with the people capturing the material on site was very valuable when creating the synthesize 3D footage to train object recognition.
After Adams presentation of the VFRAME tools the workshop continued with Jeff Deutch taking us through processes of verifying the footage. Whereas machine learning is developed to flag relevant material for the activists, a important part of the labor is still manually done by humans. One of the important tasks is to connect the material together validating the date so it can be used as evidence. Jeff us a couple of examples how counter narratives to state news was confirmed by using various OSINT(Open source intelligence) tools such as revers image search (google, tincan), finding Geo-location (twitter, comparing objects and satellite images from Digital Globe), verifying time (unix time stamp), extracting metadata (e.g. Amnesty’s Youtube DataViewer), and collaboration with aircraft spot organizations.
The workshop and the panel were extremely informative in terms of understanding workflows and how machine vision can be used in contexts outside surveillance capitalism. The workshop had also a hands on part in which we were to test some of the VFRAME tools. Unfortunately the afternoon workshop was way to short for this and some debugging and set up issues delayed us enough to be kicked out from the workshop space before we could get hands on trying the tools.
After the transmediale I had the chance to visit the Ars Electronica Export exhibition at DRIVE – Volkswagen Group Forum. There the VFRAME was exhibited among other artworks. It is definitely one of these projects which mixes artistic practice with research and activism emphasizing the relationship between arts and politics. Another transmediale event that related to the workshop and panel mentioned earlier was a very emotional # 31 book launch of Donatella Della Ratta’s Shooting a Revolution. Visual Media and Warfare in Syria. In the discussion there was several links between her ethnographic study and the work of the Syrian Archive.
VFRAME exhibited at the Ars Electronica Export exhibition
Talks
Opening talk by Kristoffer Gansing, Artistic Director of transmediale.
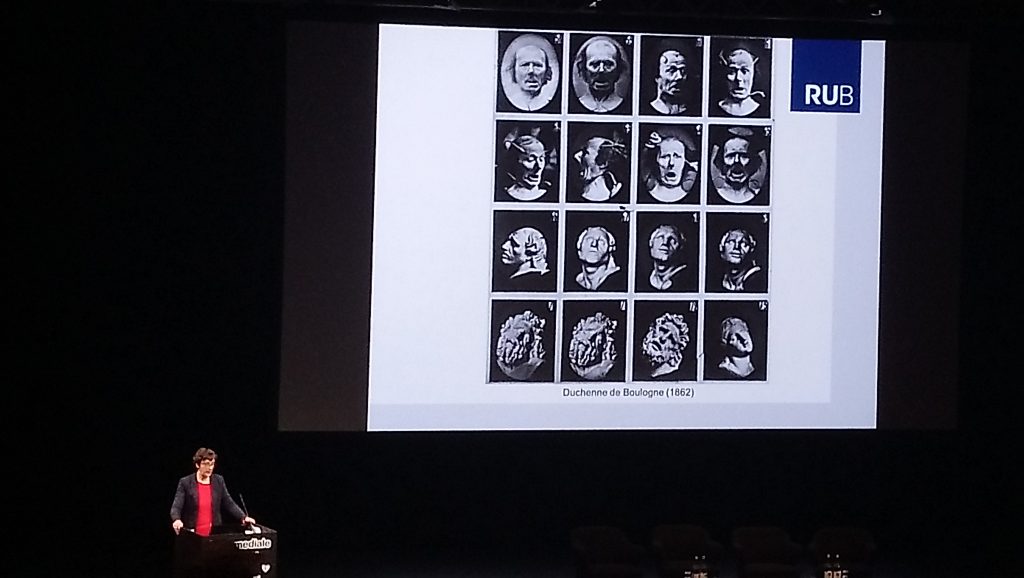
In the #01 Structures of Feeling- transmediale Opening there was some interesting references to machine vision. New York based artist Hanna Davis was presenting her current work generating emotional landscapes experimenting with generative adversarial networks and variational autoencoders. Basically the landscapes (e.g. mountains or forests) was tagged with emotions (anger, anticipation, trust, disgust, sadness, fear, joy, and surprise or ‘none’) buy Crowdflower platform workers (similar to Amazon Mechanical Turk). Then machine learning algorithms were feed with the data set to generate “angry forests” or “sad mountains” etc. The 20 minute talk was definitely a teaser to look more closely into Hannah’s work. Next up was Anna Tuschling who mentioned a number of interesting examples. With a background in psychology she talked how we have tried to understand and represent emotions coupling e.g. neurologist Duchenne de Boulogne’s work in the 1800s with facial recognition technology and applications such as Affectiva (“AFFECTIVA HUMAN PERCEPTION AI UNDERSTANDS ALL THINGS HUMAN – 7,462,713 Faces Analyzed”) and Alibaba Group’s AliPay’s ‘Smile to Pay’ campaign in China.
Anna Tuschling taking about neurologist Duchenne de Boulogne’s workStructures of Feeling – transmediale 2019 opening panel with Hanna Davis, Anna Tuschling and Stefan Wellgraf, moderated by Kristoffer Gansing
From the #12 Living Networks Talk, Asia Bazdyrieva’s & Solveig Susse’s Geocinema awoke my interest. They considers machine vision technology such as surveillance cameras, satellite images an cell phones together with geosensors an cinematic apparatus sensing fragments of the earth. The # 15 Reworking the Brain Panel with Hyphen-Labs and Tony D Sampson was not quite what I had expected, yet Sampson’s presentation connected with the readings we done on the non-conscious (N. Katherine Hayles, Unthought). He reflected on how brain research has started to effect experience capitalism (UX Industry) asking “What can be done to a brain?” and “What can a brain do?”. In the Q&A Sampson revealed a current interest in the non-conscious states of the brain while sleep walking which I found intriguing.
NeuroSpeculative AfroFeminism (NSAF) by Hyphen LabsNonconscious debate Hayles/Sampson.
In my opinion one of the best panels was #25 Algorithmic Intimacieswith !Mediengruppe Bitnik and Joanna Moll, moderated by Taina Bucher. The panel discussed the deepening relationship between humans and machines and how it is mediated by algorithms, apps and platforms. The cohabitation with devices we are dependent on was discussed through examples of the artists works. !Mediengruppe Bitnik presented three of their works Random Darknet Shopper, Ashley Madison Angels and Alexiety. All of the works asked important questions about intimacy, privacy, trust and responsibility. The Ashley Madison Angels work bridged well with Joanna Molls work the Dating Brokers illustrating how our most intimate data (including profile pictures and other images) are shared among dating platforms or sold forward capitalizing on our loneliness. Ashley Madison is a big dating platform that is specially marketed to people who feel lonely in their current relationship (marriage), so it encourages adultery. In 2015 the Impact Team hacked their site, while the company did not care too much about the privacy of their customers, the hackers dumped the breach making it available for everyone. The dump was large containing a huge amount of profiles, and also source code and algorithms. It became an unique chance for journalist and researchers to understand how such services are constructed. Among others !Mediengruppe Bitnik was curios to understand how our love life is orchestrated by algorithms. What was discovered from the breach was an imbalance between male and female profiles. The service lacked female profiles and due to this they had installed 17.000 chat bots. !Mediengruppe Bitnik thought that there would be amazing AI developments in creating these bots. They were to have conversations with clients from different cultures, in various languages about a number of topics. But it turned out to be very basic chat bots, with 4-5 A4 pages of erotic toned hook up lines. A well choreographed flirting was enough to keep up the conversation and the client paying for chat time. In the Ashley Madison Angels video installation the pick up lines are read by avatars wearing black “Eyes Wide Shut” type of venetian masks. After the talk I asked Carmen ( !Mediengruppe Bitnik ) about the masks. She told me that they were a feature provided by the service, as a playful joke to add on your profile image. Actually all the bots profile images were masked with the feature so that the profile images could not be run through e.g. googles revers image search to confirm abuse of profile images. In the end the chat bots were using 17000 stolen, maybe slightly altered id’s of existing people. Carmen also noted that the masks would not work anymore whereas google can now recognize a images as a duplicate using just parts of the image/face. In connection to the Ashley Madison bots also the army of human CHAPTA solvers was mentioned in the talk. There is a effective business model exploiting cheap labor to solve CHAPTAS for bots almost in real time.
!Mediegruppe Bitnik talking about their work Ashley Madison Angels.
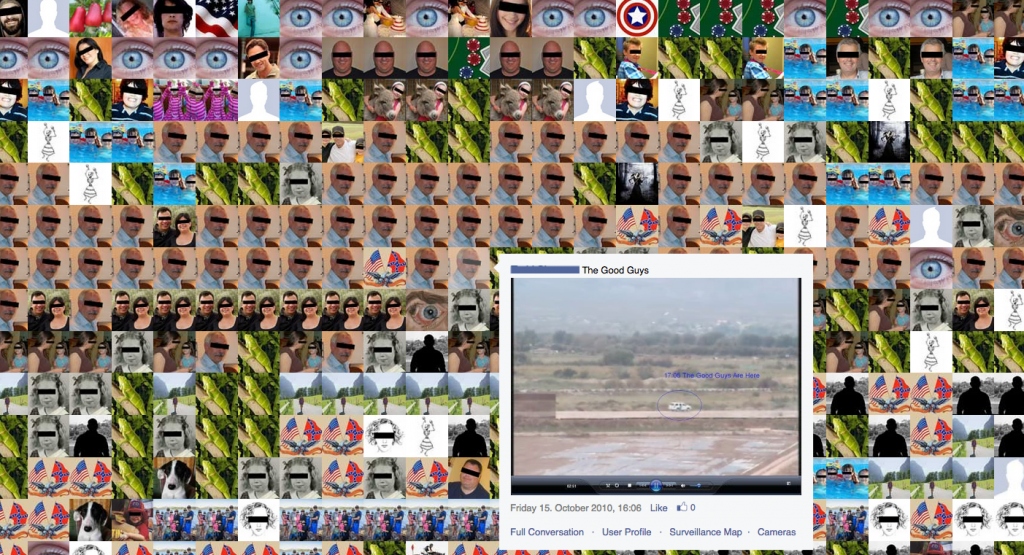
Joanna Moll continued talking about the “dating business”. Together with the Tactical Tech Collective she has researched in how dating profile data is shared and sold by data brokers. For her work Dating Brokers she bought one million profiles for 136€. These profiles (partly anonymised) can be browsed through using the interface she created. Additionally a extensive report on the research part of the project can be read in The Dating Brokers: An autopsy of online love. The report describes common practices of so called White Label Dating. While no one wants to be the first person registering onto a dating platform there is a common practice to either share data among groups of companies. When agreeing to the user terms ones profile can be shared among “partners” that can reach up to 700 companies having legal access to the data. Additionally the profiles are sold in bundles like the one million profiles Joanna bought from the dating service Plenty of Fish. The data set included about 5 million images, and I would not wonder if these images end up fed into neural networks hungry for faces to recognize.
Joanna Moll reporting on her research for The Dating Brokers: An autopsy of online love.Dating profiles can be shared among partners, this means your data can legally be breached up to 700 companies.
There was several interesting talks about the commons, machine learning, affect and other topics, yet the talks described here more or less relate to my research.
Exhibitions
Somewhat disappointed I had to realize that there was no transmediale exhibition exhibition this year. As a part of the Partner program there was an related exhibition Creating Empathy at Spectrum Project space, but due to unpractical opening times I was not able to make it there. Transmediales partner festival CTM 2019 hosted an exhibition Persisting Realities which I was able to visit. I was exited to see Helena Nikonole’s deus X mchn that uses after reading about the work in her essay in the book Internet of Other People’s Things (edited by me and Andreas Zingerle). Therefor I was a bit disappointed in the presentation of her work with partly dysfunctional screens and media players. The work uses both surveillance cameras and AI making us aware of being watched. Some of the other works awoke my curiosity, yet over all the exhibition left me unemotional. My exhibition experience was saved from being a total flop by the Ars Electronica Export exhibition which was outside the transmediale program and therefore you can read more about it here.
Helena Nikonole’s work deus X mchn in the Persisting Realities exhibition.Detail of Helena Nikonole’s work deus X mchn.
Screenshot: detail from https://wwwwwwwwwwwwwwwwwwwwww.bitnik.org/assange/ webpage.
DELIVERY FOR MR. ASSANGE, 2013 !Mediengruppe Bitnik A live mail art piece (Parcel with web camera, live streamd video, twitter)
RRRRRRRRRRRRRRRRRRRRRRRRRRRADICAL REALTIME About the artwork/ documentation of the artwork https://wwwwwwwwwwwwwwwwwwwwww.bitnik.org/assange/
VR installation view from ZKM. Source: http://marclee.io/en/10-000-moving-cities-same-but-different-vr/
Autonomous Trap 001, 2017 James Bridle
Ground markings to trap autonomous vehicles using “no entry” and other glyphs. Performance of a salt circle trap, Mount Parnassus, 14/3/17.
To better understand some of the artworks that I am working with I also need some more technical understanding of Machine learning with images, AI and neural networks. Below I collected some of my readings and notes from last week.
Machine vision and AI
Computer science: The learning machines
Nicola Jones
08 January 2014 https://www.nature.com/news/computer-science-the-learning-machines-1.14481
– Google Brain case (deep neural network)
– Deep learning
– Short review of computer vision developments (rule based to neural networks)
– ImageNet competition
– crowd-sourced online game called EyeWire (https://eyewire.org/) to map neurons in the retina
– “Deep learning happens to have the property that if you feed it more data it gets better and better,”
– Modeling the brain might not be the best solution, there are other attempts like “reason on inputted facts” (IBM’s Watson).
– Probably deep learning is going to be combined with other ideas.
Building High-level Features Using Large Scale Unsupervised Learning
Quoc V. Le, Marc’Aurelio Ranzato, Rajat Monga, Matthieu Devin, Kai Chen, Greg S. Corrado, Je Dean, Andrew Y. Ng
12 Jul 2012 https://arxiv.org/pdf/1112.6209.pdf
– A paper on improving face recognition (also cats and body parts)
– How deep learning is a methodology to build features from “unlabeled data” (self-taught learning not supervised or rewarded)
– Core components in deep networks: dataset, model and computational resources.
– Uses sampling frames from 10 million Youtube Videos
Dermatologist-level classification of skin cancer with deep neural networks
Andre Esteva, Brett Kuprel, Roberto A. Novoa, Justin Ko, Susan M. Swetter, Helen M. Blau & Sebastian Thrun
02 February 2017 (A Corrigendum to this article was published on 28 June 2017) https://www.nature.com/articles/nature21056
– Deep convolutional neural network and a dataset of 129450 clinical images used to train machines to recognized skin cancer.
– Future possible application to make low-cost diagnosis with smartphone.
Can we open the black box of AI?
Davide Castelvecchi
05 October 2016 https://www.nature.com/news/can-we-open-the-black-box-of-ai-1.20731#sheep
– with historical perspective how neural networks developed
– networks are as much a black box as the brain
– neural networks and brains do not store information in blocks of digital memory, they diffuse the information which makes it hard to understand.
– “some researchers believe, computers equipped with deep learning may even display imagination and creativity”
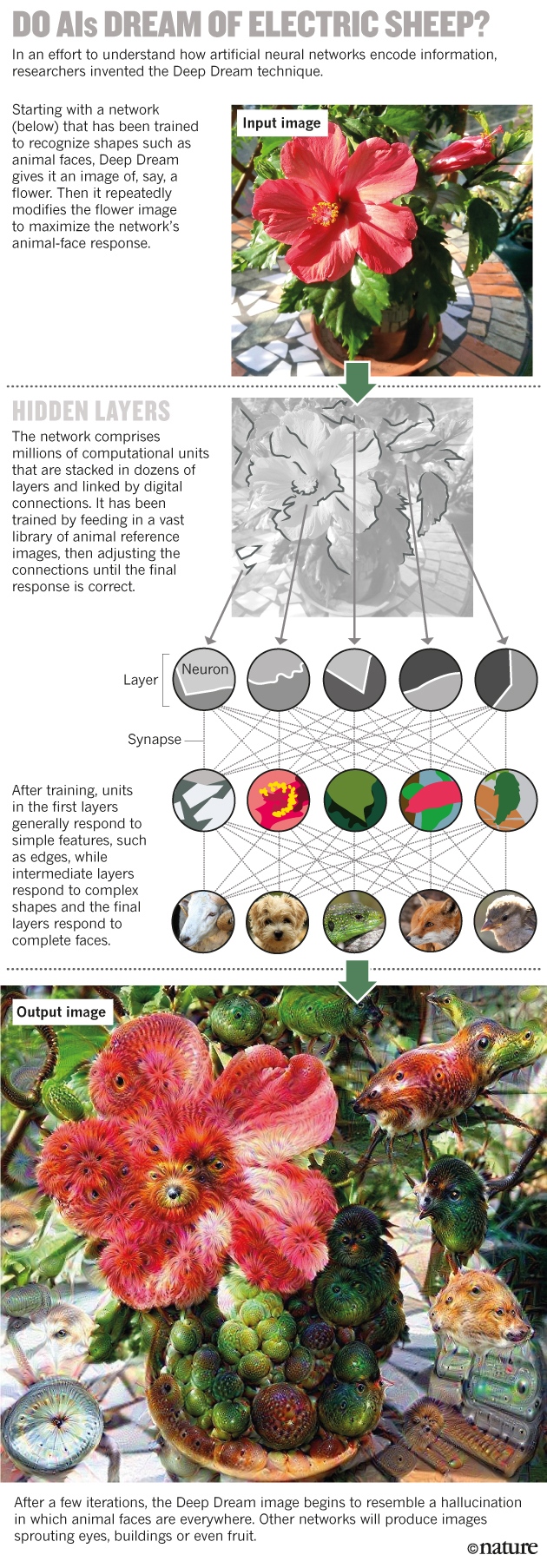
– Deep Dream how networks produce images
– we are as far from understanding these networks as we are from understanding the brain
– therefore used with caution (cancer example)
– the network has understood something but we have not
– to understand how the network was learning they ran the training in reverse -> same approach with Deep Dream (artworks Tyka?). Deep Dream made available online.
– “fooling” problem causes problems – hackers could fool cars drive into billboards thinking they were streets etc.
– “You use your brain all the time; you trust your brain all the time; and you have no idea how your brain works.”
BIAS and AI
AI can be sexist and racist — it’s time to make it fair
James Zou & Londa Schiebinger
18 July 2018 https://www.nature.com/articles/d41586-018-05707-8#ref-CR10
– Bias is not unique, but increased use of AI makes it important to address
– Skwed data:images by scraping Google images or Google News, with specific terms, annotated by graduate students or Amazons Mechanical Turk leads to data that is encode gender, ethnic and cultural biases.
– ImageNet that is most used in computer vision research has 45% of its material from USA (home to only 4%), China and India with much bigger populations contributes just a fraction of the data.
– Examples: Skin color in cancer research, western bride vs. Indian bride, misclassify gender of darker-skinned women.
– Suggested “fixes”: Diverse data, standardized metadata as a component of an peer-review-process, retraining, in crowd sourced labeling basic information about the participants should be included and information about their training. Another algorithm testing the bias of the learning algorithm (AI audit), designers of algorithms prioritizing to avoid biases.
– ImageNet 14 million labeled images USA 45.4%, Great Britain 7,6% Italy 6.2%, Canada 3% Other 37.8%
– Who should decide which notions of fairness to prioritize?
– Human-Centered Ai initiative in Standford University CA (social context of AI)
Bias detectives: the researchers striving to make algorithms fair
Rachel Courtland https://www.nature.com/articles/d41586-018-05469-3
20 June 2018
– About predictive policing and AI
– AI Now Institute in New York University (social implications of AI)
– A task force in NYC investigating how to publicly share information about algorithms to examine how bias they are.
– GDPR in Europe is expected to promote algorithmic accountability.
– Enhancing exciting inequality e.g. use of police records in the states. The algorithm is not bias, but the data and how it was collected in the past.
– Questions of how define fair
– Examples of Auditing AI from outside (mock passengers, dummy cv’s etc.)
– Researchers asking if we are trying to solve the right problems (predicting who is appearing in court vs. how to support people to appear in court)
Investigating the Impact of Gender on Rank in Resume Search Engines
Le Chen, Ruijun Ma, Anikó Hannák, Christo Wilson https://dl.acm.org/citation.cfm?doid=3173574.3174225
– Overview on studies on algorithmic biases (AI audits).
– Investigating gender inequality in Job Search Engines
– Concludes that there is unfairness but the audit can not isolate the hidden features that may be causing it.
– A lot of limitations in these types of AI audits
Reform predictive policing
Aaron Shapiro
25 January 2017 https://www.nature.com/news/reform-predictive-policing-1.21338
– Overview of how predictive policing is currently used
– Overview of tech used in predictive policing and what kind of data is used:
“The data include records of public reports of crime and requests for police assistance, as well as weather patterns and Moon phases, geographical features such as bars or transport hubs, and schedules of major events or school cycles.”
– Concerns: no agreement on should predictive systems prevent crime or catch criminals, racial bias in crime data and bias on reported crime data.
There is a blind spot in AI research https://www.nature.com/news/there-is-a-blind-spot-in-ai-research-1.20805
Kate Crawford & Ryan Calo
13 October 2016
– no agreed methods to assess how AI effect on human populations (in social, cultural and political settings)
– The rapid evolving of AI has also increased demand for so called “social systems analyses of AI”.
– No consensus on what counts as AI
– Tools to avoid bias: compliance, ‘values in design’ and thought experiments
– Examples of images and algorithms: Google mislabeling African americans with gorillas and Facebook censoring Pulitzer-prizewinning photograph with a naked girl fleeing the napalm attack in Vietnam.
– Suggests a social-systems analysis that examines AI impact on several states: conception, design, deployment and regulation
The Dataset Nutrition Label: A Framework To Drive Higher Data Quality Standards
Sarah Holland, Ahmed Hosny, Sarah Newman, Joshua Joseph and Kasia Chmielinski
Draft from May 2018 https://arxiv.org/ftp/arxiv/papers/1805/1805.03677.pdf
Prototype: https://ahmedhosny.github.io/datanutrition/
– Survey on best practices of ensuring quality of data to train AI
– Survey shows no best practices, self learned
– “Dataset Nutrition Label” inspired by labeling food, “Privacy Nutrition Label” from World Wide Web Consortium improved legibility of privacy policies.
– Ranking Facts labels algorithms
– “Datasheets for Datasets,” including dataset provenance, key characteristics, relevant regulations and test results, potential bias, strengths and weaknesses of the dataset, API or model and suggested use.
– Data Statements for NLP (natural language processing)
– “Dataset Nutrition Label” should improve data selection and therefore result in better models.
Datasheets for Datasets Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, Kate Crawford
9th Jul 2018 https://arxiv.org/pdf/1803.09010.pdf
– Another initiative to standardize datasets used in machine learning based on practices in electronics industry.
Anticipating artificial intelligence
Editorial
26 April 2016 https://www.nature.com/news/anticipating-artificial-intelligence-1.19825
– Researchers concerned about AI (Luddite Award)
– Not that machines and robots outperform humans, but:
– the surveillance and loss of privacy can be amplified
– drones making lethal decisions by themselves
– smart cities, infrastructures and industry becoming overdependent on AI
– mass extensions in jobs, leading to new types of jobs and societal change (permanent unemployment increases inequality)
– Could lead to wealth being even more concentrated if gains from productivity is not shared.
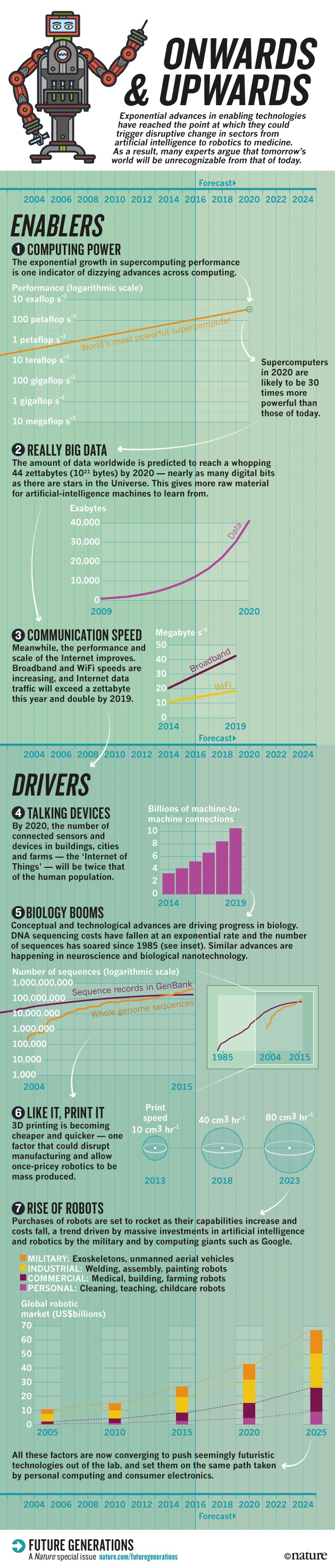
Illustrations by Greygouar; Design by Wes Fernandes/Nature; Sources: 1. top500; 2. IDC Digital Universe Study, 2012; 3. Cisco Visual Network Index (VNI), 2015; 4. Cisco VNI Global IP Traffic Forecast, 2014–2019; 5. NCBI; 6. EPSRC; Direct Manufacturing Research Center; Roland Berger; 7. International federation of robotics, Japan Robot Association; Japan Ministry of Economy, Trade & Industry; euRobotics; BCG
In November I had the chance to visit the opening of the group exhibition ‘sensu lato :: im weiteren Sinne’ at Akademie Graz, and learn more about the exhibited works during a “Making of Presentation.”
One of the most interesting works was the Neuleittorgasse. To generate the images seen in the photo above a neural network was feed with over 100.000 images of streets in Graz. The idea was to generate new street views using a modified version of the “Deep Convolutional Generative Adversarial Network”. The artwork is a part of experiments that a group of artist conducted within the framework of the ‘Im Netz der Sinne’ project organized by mur.at in Graz, Austria.
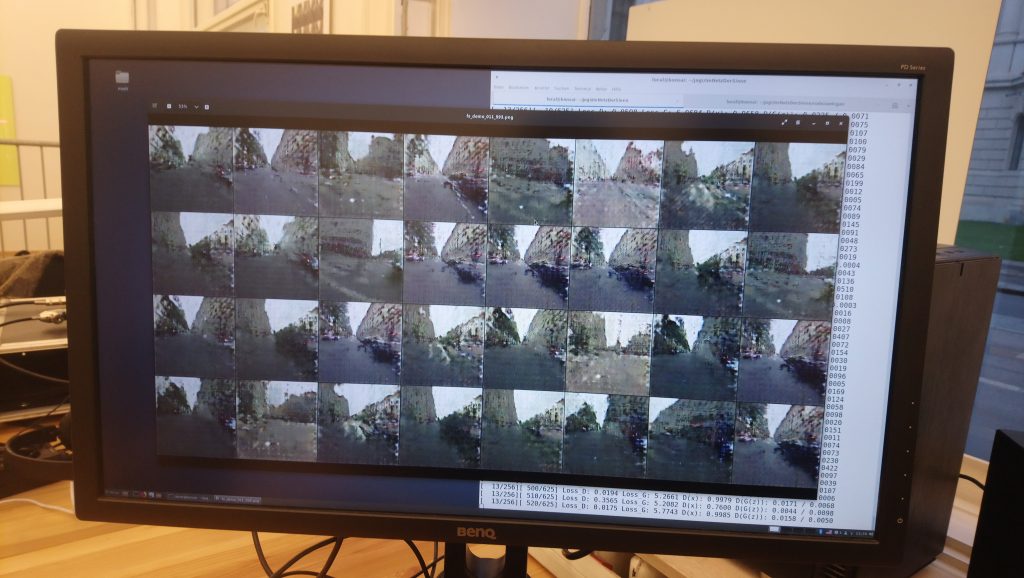
Machine Learning in action. Photo: KairUs
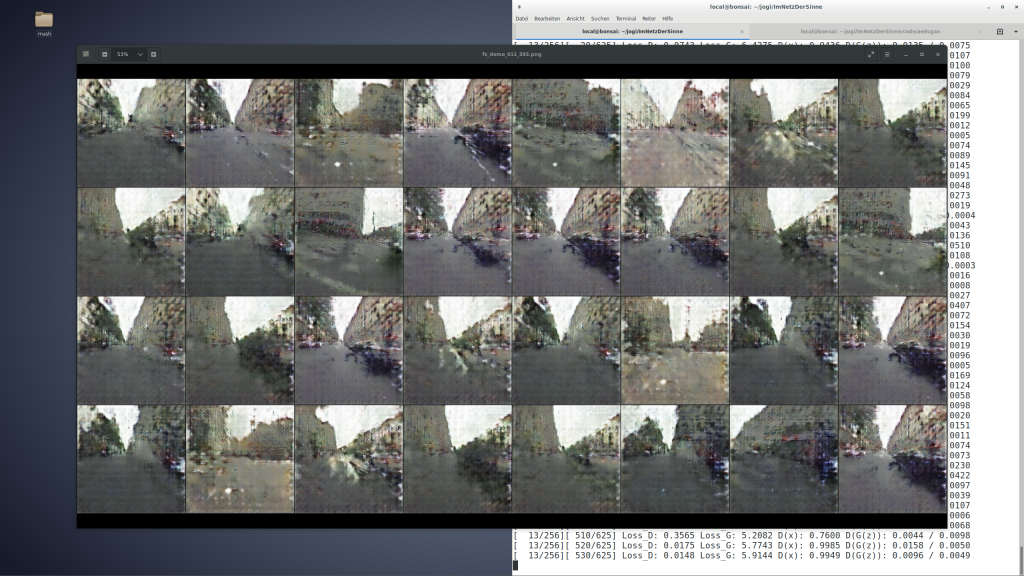
During the presentation Jogi Hofmüller showed me how the neural network processed iterations of images (image abow). How the generator was producing “fakes” or “own versions” of the the images based on the 100.000 street views from Mappilary. In a Generative Adversarial Network the generated images are then approved or not by the so called discriminator. This enables the machine to learn and getting better in generating images. It is described to be a kind of competition between the generator and the discriminator. The generator trying to make images as close to the ones in the data set and kind of fooling the discriminator, whereas the discriminator is getting better in distinguishing between the images from the data set and the generated ones.
Making of. Screenshot provided by Jogi Hofmüller
The artists described the process of working with machine learning as very fascinating. In the start of the process when the algorithm is just starting to extract features from the data, be it images or sounds the first generative examples are just noise. Slowly after repeating the loop hundreds of times the images start to show features in this case of streets, buildings, cars and trees hovering in the air. The image gets clearer until suddenly only gray noise is produced again. The generator was trying something new.
Training a neural network to recognize orchid’s. Photo by KairUs
To better understand the process of machine learning, members of the machine learning group were conducting exercises common among computer science students. One of them was to train a neural network. One of the members has been collecting images of orchids for decades and this collection was used to train a neural network. The results were also exhibited providing deeper understanding of various steps of machine learning as well as creating a timeline of how and what the group had learned about machine learning.
Generated orchids in detail. Photo by KairUsSelection of machine generated orchids. Photo by KairUs
After training the neural network with orchid images from the data set new images of orchids were machine generated. In the presentation the artists explained how the real orchids actually imitate insects and in the generated images this aspect was emphasized.
Also other aspects of object recognition in computer vision was discussed in the making of session and represented in the artworks. For example the images above describe how the machine processes images to recognize human objects in images. While our human eye is trained to recognize clusters of objects it gets a great deal harder for the machine to recognize groups of things.
sensu lato :: im weiteren Sinne
at Akademie Graz 23.11.2018 – 14.12.2018
Im Zentrum der künstlerischen Arbeit von mur.at steht 2018 das Thema Machine Learning. Dieser Begriff bezeichnet ein Verfahren, bei dem Maschinen aus einer Vielzahl von Beispielen Muster extrahieren und diese verallgemeinern können. Weitgehend verborgen beeinflussen derartige Systeme mehr und mehr unsere Leben.
In der Ausstellung sensu lato :: im weiteren Sinne präsentiert das Projektteam die Ergebnisse der knapp einjährigen Auseinandersetzung mit verschiedenen Formen maschinellen Lernens.
Titel der Ausstellung ist “Sensu lato – im weiteren Sinne“
Künstler*innen aus der mur.at Community
Beteiligte/Künstler*innen:
Merna El-Mohasel
Christian Gölles
Jogi Hofmüller
Reni Hofmüller
Dietmar Jakely
Margarethe Maierhofer-Lischka
Elena Peytchinska
Martin Rumori
Dorian Santner
Martin Schitter






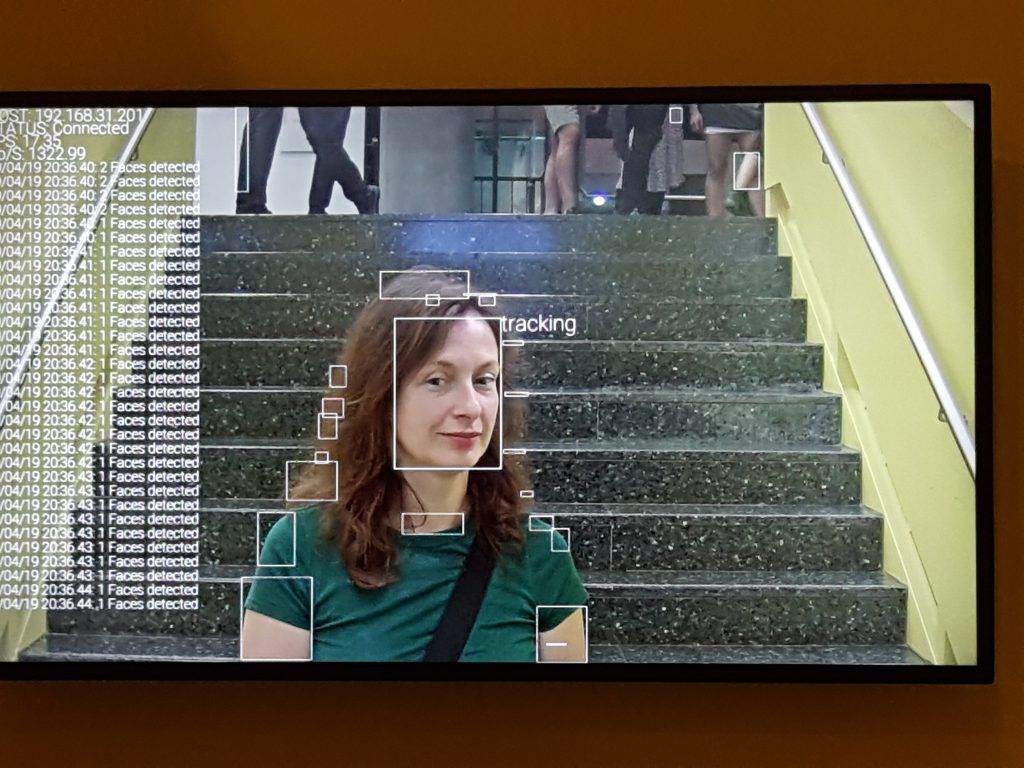 When entering the exhibition the first thing one faces is facial recognition. Later one realizes being part of the
When entering the exhibition the first thing one faces is facial recognition. Later one realizes being part of the