
Earlier in the autumn the basement of Ars Electronica Center had been reopened with two totally new exhibition, both relevant for the Machine Vision Project: Understanding AI and Global Shift. We visited these exhibitions both for the festival pre-opening program and late for a deeper dive into the very information rich and detailed exhibitions. All together we probably spent 5 hours there without really able to cover everything in depth.
Understanding AI
What is artificial intelligence? And what do we actually know about human intelligence? How intelligent can artificial intelligence be in comparison? And more importantly: what effects will the advances in this field have on our society?
https://ars.electronica.art/center/en/exhibitions/ai/


Understanding AI combines artworks, research, visualizations and interactive experiences trying to explain what AI is now as in Machine Learning. The exhibition emphasizes on the positives of AI, however, between the lines also issues of privacy, biases and other “highly questionable” use of AI is brought forth. Whereas the Uncanny Values exhibition in Vienna was bringing fort social, economical, ethical and democratic issues from a discourse around ethical/fair use of AI the Ars Electronica exhibition was very didactic and aimed to explain the technology in a very detailed way.
Following some highlights from the perspective of my research:

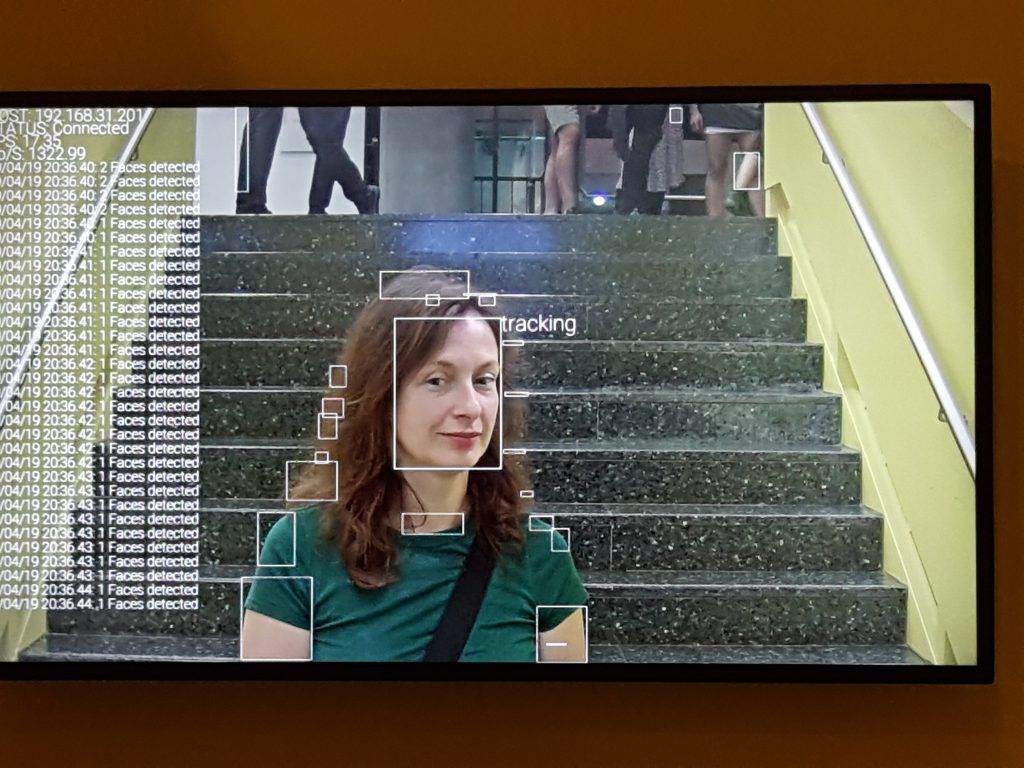 When entering the exhibition the first thing one faces is facial recognition. Later one realizes being part of the
When entering the exhibition the first thing one faces is facial recognition. Later one realizes being part of the
WHAT A GHOST DREAMS OF (2019) artwork by artist collective H.O. According to the artist the artwork questions:
What do we humans project into the digital counterpart we are creating with AI? It is getting to know our world without prior knowledge and generating data that never existed. What are the effects of using AI to produce works of art? Who holds the copyright? And what is AI, the “ghost,” dreaming about, and what does that mean for us as human beings?


Getting down the stairs to the basement we naturally continue to explore questions about facial and emotion recognition. Mixed on a wall are research papers, websites, industry apps, viral deep fake videos and (artistic) research such as Adam Harvey’s Mega Pixels or Gender Shades by Joy Buolamwini team.The mix brings applications of facial and emotion detection both showing how advanced the technology however questioning the ethical aspects of it as well as. Research shows how “fake” faces produced and getting more realistic bringing also forth problematic uses of deep fakes.

On the long wall one can try Affectiva’s emotion detection app. One can also watch Lucas Zanottos film in which he used very simple everyday objects to express feelings, together with the emotion detection app these works raises questions of how emotions are mapped to our facial expressions.
Further the visitor can read how neural networks were trained to recognize criminal faces in a Chinese study, and how e.g. Amazon Face recognition failed to mach lawmakers faces.
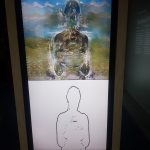
One section of the wall questions what can be read in a face followed by examples such as face2gene and faception the first an app to recognize genetic syndrome from a child’s picture and the second profiling faces into categories such as High IQ, Poker face, Terrorist or Pedophile. Even if info layers refer to Physiognomy here a sharper tone on condemning such applications and revealing their dangers would have been beneficial. Also the the highly alerting study on training AI to recognizes sexual orientation from facial images is only paired with a question if AI understands what it sees, rather than implications of making such an study or application in the first place. How ever a section of the wall is dedicated to problematic use of facial recognition in predictive policing and oppressive use in a surveillance state such as China. The anecdote on the wall referring to public shaming of jail walkers.

One section on the wall is turning our attention to the generation of faces using neural networks. The “Obama Deep Fake” by Researchers at the University of Washington and AI generated news anchors are paired with artist Matthias Nießner face2face in which he plays the puppet master with Trumps face. In addition a research on generating very realistic fake faces by a company called NVIDIA shows how fast such fakes are getting harder to recognize. Here I would like to seen a segment on how spoofing fakes is also very important as described e.g. by artist Kyle McDonald




















Opposite to the “face wall” a piece called GLOW developed by Diederik P. Kingma, Prafulla Dhariwal; OpenAI, gives a interactive experience linking data sets with characteristics. A set of 16 characteristics can be adjusted for the generated image. Playing around with the thing for a while showed for example that when maximizing the young parameter and glasses the glasses were very faded, however when going towards older the glasses got more visible showing that in the trained data set people tagged old were wearing glasses are more often.









Just the section of faces could have been an own exhibition, however we are just starting to get warm. Another big part of the exhibition was dedicated to explain various AI networks e.g. modeled on moths olfactory system or intelligent navigation systems modeled on rats. Interactive displays were also used to explain how current neural networks are modeled on neurons in the human brain. Here I learned about the scientific image technique “Brainbows”.
A section was dedicated to explain research in the field of cognition and consciousnesses. On one of the screens I got immersed into a work of Kurzgesagt (In a Nutshell) called The Origin of Consciousness – How Unaware Things Became Aware, and it turns out they have a whole channel of shot animations dealing with philosophical and scientific questions.
Further on one could experience trainrt ing of networks on several levels. From how the weights and biases of single neurons change when training a network to training a system to recognize the predators of a mouse. This part of the exhibition was very well done, however, it was like an updated version of a science museum rather than a art exhibition. Though this is very much in style what Ars Electronica center is. An info layer of short texts and images also explained machine learning terminology e.g. what is the difference between Generative Adversarial Network, Recurrent neural network and a Convolutional neural network or explaining terms such as Latent space or
Activiation Atlas.








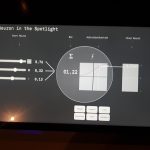






“How machines see” was also a topic in several works in the exhibition. A wall of screens depicted how various layers in a neural network recognized various features. The work visualized live layers, convolution and filters, and how the artifacts shown in front of a web-camera finally was recognized and labeled either successfully or not. Hence visitors could test the accuracy of the trained network and at the same time get insight onto how current AI “sees” and “understands” objects.

This work on Neural Networks Training developed by The Ars Electronica Future Lab was the most impressive attempt to open the black box of machine learning in computer vision.




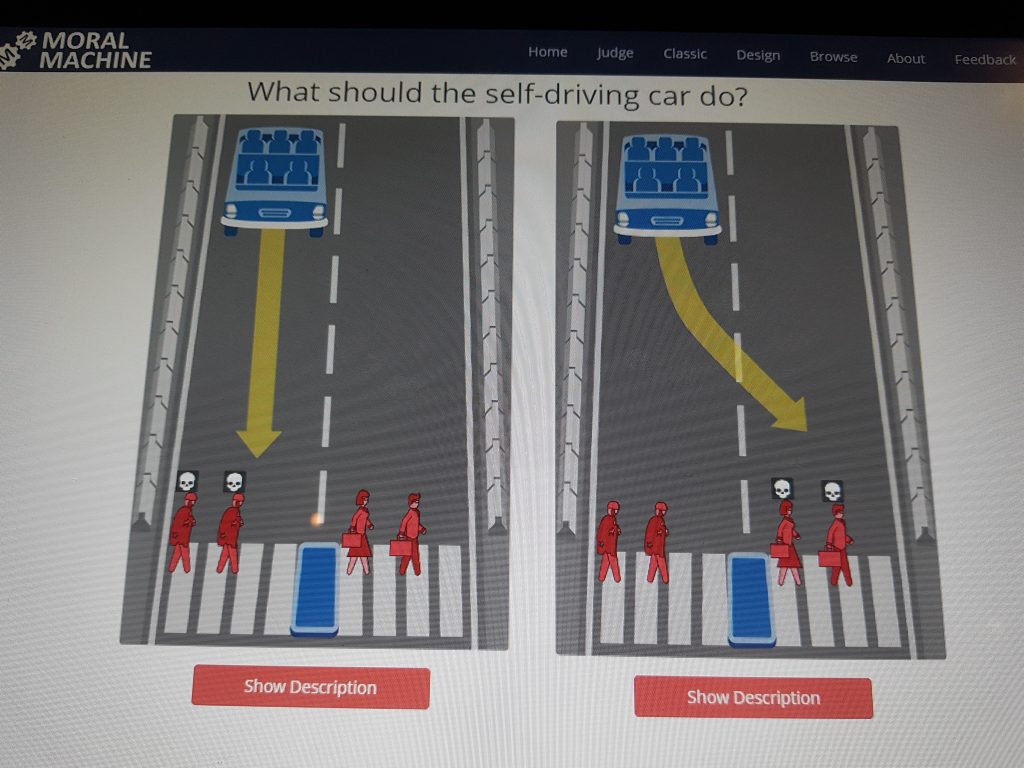
How machines “see” environments e.g. is of course a big issue in computer vision. A section of the exhibition was exploring the challenges to develop self driving cars and obviously in traffic it is crucial that the communication between pedestrians and eventually self driving cars is smooth. Various aspects of the challenges to design an autonomous car was on display ranging from “Looking Through the Eyes of a Tesla Driver Assistant” to MIT’s Moral Machine a platform for gathering human perspective on moral decisions made by machine intelligence such as self-driving cars.






Korean collective Seoul LiDARs uses industrial technology in various artistic experiments. Their Volumetric Data Collector a bulky wearable is using 3D laser sensors (Lidar) which are usually implemented in autonomous vehicles. A video work illustrates how such tech extends the sensory organ of a human body while walking in Seoul e.g. on the shamanistic mountain Ingwasan.
Seoul LiDARs from Sookyun Yang on Vimeo.
Kim Albrechts Artificial Senses approaches artificial intelligence as an alien species trying to understand it by visualizing raw sensor data that our machines collect and process. In his work he “tames” the machine by slowing it down to be grasped by human sensory. We move away from the vision to other senses, however, the when sensor data of location, orienting, touching, moving and hearing are visualized the work brings me to the question of what is machine vision. In a digital world in which machines actually just see numbers any sensor input can be translated to visuals. Hence what the “machines sees” are data visualizations and any sense can be made visible for the human eye. However, the machine dose not need this translation. Kim questions the similarity of the images:
“A second and more worrying finding is the similarity among many of the images. Seeing, hearing, and touching, for humans, are qualitatively different experiences of the world; they lead to a wide variety of understandings, emotions, and beliefs. For the machine, these senses are very much the same, reducible to strings of numbers with a limited range of actual possibilities. “
Source: https://artificial-senses.kimalbrecht.com/
Both sensing and mirroring human behavior is demonstrated in Takayukis SEER: Stimulative Emotional Expression Robot. In this work the machine is using face detection and eye tracking to create an interactive gaze creating an illusion that the robot is conscious of its surrounding. Facial motion tracking mirrors our emotions towards the robot and expresses it back simply using an soft elastic wire to draw a curve the robots eyebrows. According to the artist the experiment is not to answer the philosophical theme “Will a robot (or computer) obtain a mind or emotions like mankind”, rather it is reflecting back a human produced emotion.
The exhibition would not be complete if it would not raise the question: Can AI be creative? Followed by the recognizable Neural Aesthetics. Among others these section features projects such as Pix2Pix Fotogenerator, Living Portraits of e.g. Mona Lisa and Marilyn Monroe, and interactive installations such as Memon Akten’s Learning to See: Gloomy Sunday (2017) and ShadowGAN developed by the Ars Electronica Future Lab. When such tools generate new unique artifacts it is tempting to read machine creativeness into it, however several artist statements describe how human and machine creativity intertwine and that the artist is still doing a lot of decisions. This would rather lean towards being a new generative art technique and we will for sure see more tools such as NVIDIA’s GauGan which also could be tested in the Ars Electronica center.The development of such tools are directed to motion/graphic designers in advertisement agencies to produce cost efficient images. Drawing photo realistic landscapes or generating realistic photos of non-existing people helps agencies to avoid image and model royalties and expensive trips to photo shoot in exotic locations.










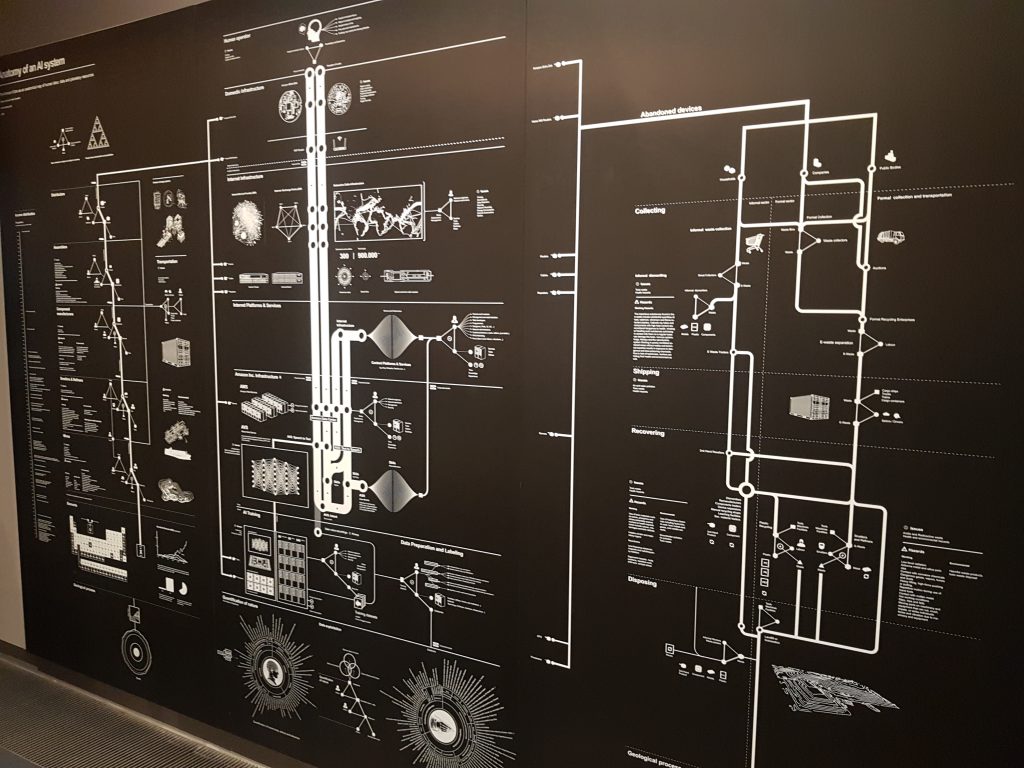
Last (depending of how one navigates trough the exhibition), but not least, a wall dedicated to the wonderfully complex Anatomy of an AI system (2018) illustrations by Kate Crawford and Vladan Joler.
—-Acknowledgements—-
Photo credits of this blog post goes to our lovely Machine Vision project assistant Linn Heidi Stokkedal and some of the photos are taken by me as well.